Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher Ré, Clark Barrett, Zhangyang Wang, Beidi Chen
Large Language Models (LLMs) have ushered in a remarkable era in natural language processing, empowering machines to generate remarkably human-like content with unparalleled precision and fluency. Nevertheless, the present landscape of LLMs deployment confronts two key challenges:
- Expensive KV Cache Costs: In addition to the extensively studied hindrances associated with model size and the quadratic expenses of attention layers, the problem of the size of the KV cache, which stores the intermediate attention key and values during generation to avoid re-computation, is becoming increasingly prominent. For instance, a 30 billion-parameter model with an input batch size of 128 and a sequence length of 1024 results in 180GB of KV cache.
- Poor Generalization to Long (→Infinite) Sequences: Owing to hardware constraints, LLMs undergo pretraining with fixed sequence lengths, such as 4K for Llama-2. This limitation, however, imposes restrictions on the attention window during inference, rendering them ineffective in handling extended input sequences and blocking their utility in more extensive applications such as day-long conversations.
The question arises: How can LLMs effectively and efficiently generate content for infinite-length inputs? Our answer is “Heavy-Hitter Oracle.”
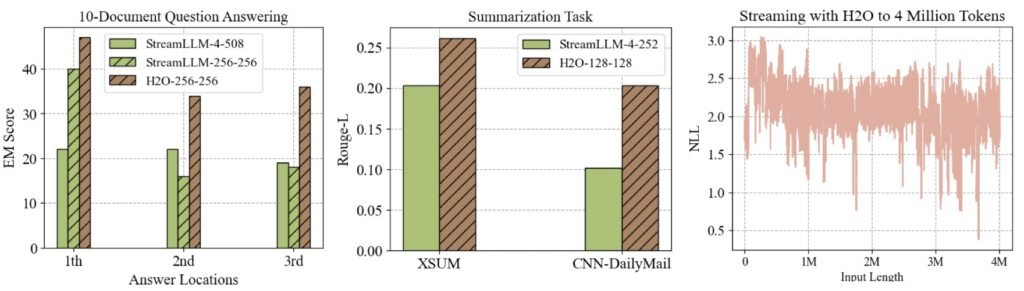
Recent works, such as StreamLLM and LM-Infinite, have shown promising potential in enabling Language Models (LLMs) to handle inputs of infinite length. They achieve this by only retaining the initial tokens and a limited local context. However, this approach may pose challenges for certain tasks where vital information lies within the middle of the input and would be lost using this strategy. We investigate it through two specific types of tasks:
- Multi-document question answering: In this task, each test sample comprises ten documents, followed by a question. The key information to answer this question is stored in one of the documents. We rearranged the crucial document’s position and found that the eviction strategy in StreamLLM or LM-Infinite can not perform well when the key document has been dropped.
- Text Summarization Task (XSUM and CNN-DailyMail): Text summarization tasks require models to generate concise summaries of lengthy texts. Effective summarization demands a comprehensive understanding of the entire document, making it challenging when crucial information is dispersed throughout the input. In particular, summarization often relies on long-context attention, and critical information may not be effectively captured within the limited local tokens.
The results are reported in Figure 1, illustrating a consistent decline in the performance of StreamLLM. Since StreamLLM will always maintain the first few tokens as well as the local tokens, regardless of various input content, such a strategy will inevitably result in the loss of crucial information and subsequently lead to a decrease in performance. In contrast, our Heavy-Hitter Oracle (H2O) delivers markedly superior performance. Also, with H2O, The model can successfully stream to 4 million tokens. Then, let’s take a close look at the details of H2O.
Heavy-Hitter Oracle:
In the early stage of our exploration, we found that the accumulated attention scores of all the tokens within attention blocks follow a power-law distribution, as shown in the figure below. This suggests the existence of a small set of tokens that are critical during generation. We denote those tokens as Heavy-Hitters (H2). Additionally, we can see the accumulated attention score of each word (in red dots) has a high correlation with their co-occurrences in the data (gray curve). In our study, we find such heavy hitters play an important role in both (1) maintaining a small cache size for efficient generation and (2) streaming LLMs of infinite-length input.

Building upon our discoveries regarding heavy-hitters, we introduce an innovative framework known as the Heavy-Hitter Oracle (H2O). H2O employs a judiciously designed greedy eviction policy based on heavy-hitters. During the generation process, when the number of tokens surpasses the allocated KV cache budget, we employ a streamlined approach. Specifically, we retain heavy-hitters based on their accumulated attention score statistics, alongside local tokens within the cache. This straightforward yet effective strategy allows us to maintain the most critical tokens for generation while minimizing the KV cache footprint.
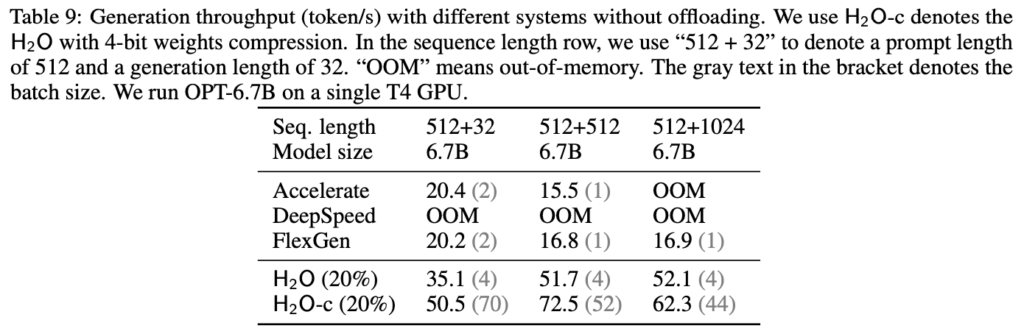
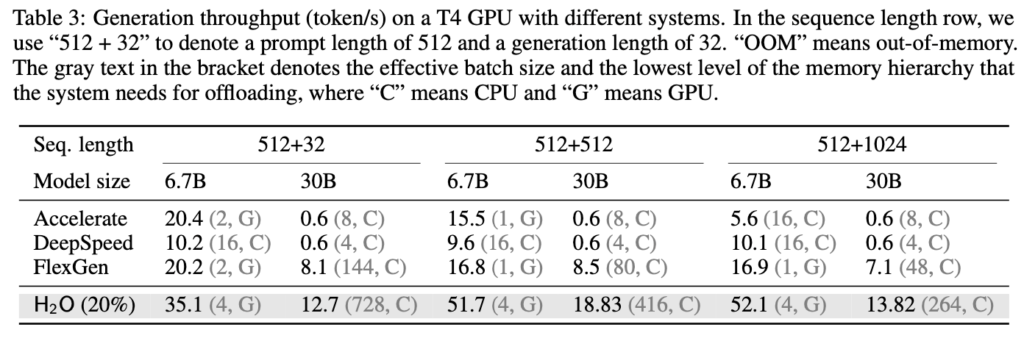
Remarkably, our experiments demonstrate the remarkable efficiency of this approach. By maintaining just 20% of the KV embeddings, H2O matches the performance of a full cache while concurrently boosting throughput by a substantial margin (3 to 29 times), compared to other leading inference systems such as Huggingface Accelerate, DeepSpeed, and FlexGen. This breakthrough underscores the potential of the Heavy-Hitter Oracle framework in significantly enhancing LLM inference efficiency.
Streaming LLMs with Heavy-Hitters Oracle
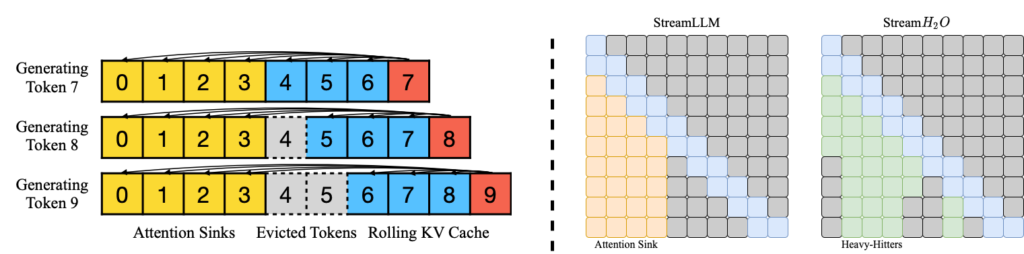
Recent works, such as “StreamingLLM” and “lm-infinite,” demonstrate the possibility of enabling LLMs to handle inputs of infinite length. These innovative approaches employ two key techniques to achieve this (as shown in Figure 3):
- Maintaining Attention Sinks: The first technique involves the retention of attention sinks, typically the initial four tokens in the input sequence. This strategic preservation serves to stabilize the computational process within the attention blocks, ensuring a smooth and consistent performance.
- Rolling KV Cache: The second technique centers around a rolling Key-Value (KV) cache mechanism. The positions of KV embeddings in the cache are shifted to the most recent tokens in the input sequence. By adapting the cache position in real-time, it enhances the model’s ability to process lengthy sequences effectively.
However, the question arises: does the KV cache effectively retain the most critical subset of KV embeddings, or does it lead to the eviction of more essential tokens? Building on our insights from identifying heavy-hitters, we explore an intriguing possibility—what if we prioritize retaining the heavy-hitters over the initial tokens in the cache? Could this approach enhance the streaming capability of LLMs towards infinite lengths, or would it yield better results?
In our experimental setup, when the sequence length surpasses the allocated KV cache capacity, we opt to retain exclusively the heavy-hitters and some of the local tokens. The illustration figures are shown in the right part of Figure 3, where StreamLLM uses the first four tokens as the attention sink while our methods dynamically maintain heavy-hitters. These heavy-hitters are determined based on their significant accumulated attention scores. Our comparative analysis, as depicted in Figure 4, reveals fascinating findings. It becomes evident that incorporating heavy-hitters into the cache leads to an even more pronounced improvement in streaming performance. This is because heavy-hitters capture a wealth of information compared to the initial tokens, further amplifying the benefits of the approach.

We further show that with H2O, we can also stream LLM to infinite input. As shown in video 1, the left part represents the baseline method. Since all the KV embeddings need to be maintained, the generation gradually becomes slower, and the generation collapses when the sequence length exceeds the pretrained context window. Finally, it stops due to Out-of-Memory. But in the right part, H2O can select the most important tokens and maintain a small KV cache, enabling efficient and effective LLM streaming.
Efficient Generation with Heavy-Hitters Oracle
Further, we demonstrate that H2O, a remarkably simple KV cache eviction policy, is capable of enhancing end-to-end throughput and reducing latency in wall-clock while maintaining generation quality across a broad spectrum of domains and tasks.
- We show that H2O can reduce the memory footprint of the KV cache by up to 5× without accuracy degradation on a wide range of model architectures (OPT, LLaMA, GPT-NeoX), sizes (from 6.7B to 175B) and evaluation benchmarks (HELM and lm-eval-harness). The following figure shows the performance of different models across different tasks. The x-axis represents the ratio of KV cache budget, and the y-axis is the corresponding performance. Local and Full stand for maintaining only the most recent tokens and all the tokens, respectively.

- Then, we demonstrate that H2O can increase the inference throughput by up to 3×, 29×, 29× compared to the state-of-the-art inference engine FlexGen, DeepSpeed, and the widely used Hugging Face Accelerate without compromising model quality.
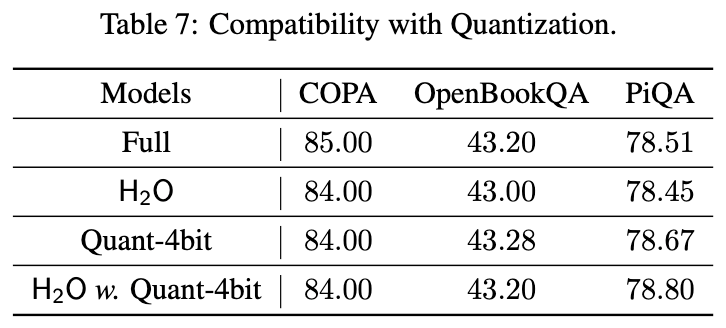
- Furthermore, we find H2O is compatible with quantization, bringing further throughput improvement (Table 9) while maintaining performance (Table 7).